Why I Almost Exclusively use AWS CDK over Terraform

I love Terraform, but over the past year i have almost exclusively used AWS CDK. But why?
CDK Pipelines make my life so much easier.
For the uninitiated, CDK Pipelines are a high level construct of CDK that enable extremely simple setup of a CI/CD pipeline.
Now that alone isn’t enough to change my life, but when you combine it with CDK cross-account bootstrapping, now you’ve just saved me from days of work and dozens of headaches.
Table of contents
- Table of contents
- Why Cross-Account Pipelines?
- Infrastructure CI/CD vs Application CI/CD
- How do I deploy?
- Conclusion
Why Cross-Account Pipelines?
I work as an AWS Consultant. Specifically, at a Premier tier APN Partner where my role as a Cloud DevOps Architect means I am constantly architecting, migrating, and building AWS infrastructure for clients.
I often encourage the use of a separate AWS account within their AWS Organization. This is a more secure and organized way of operating. However this is where the cross-account requirement comes from.
Typical AWS Organization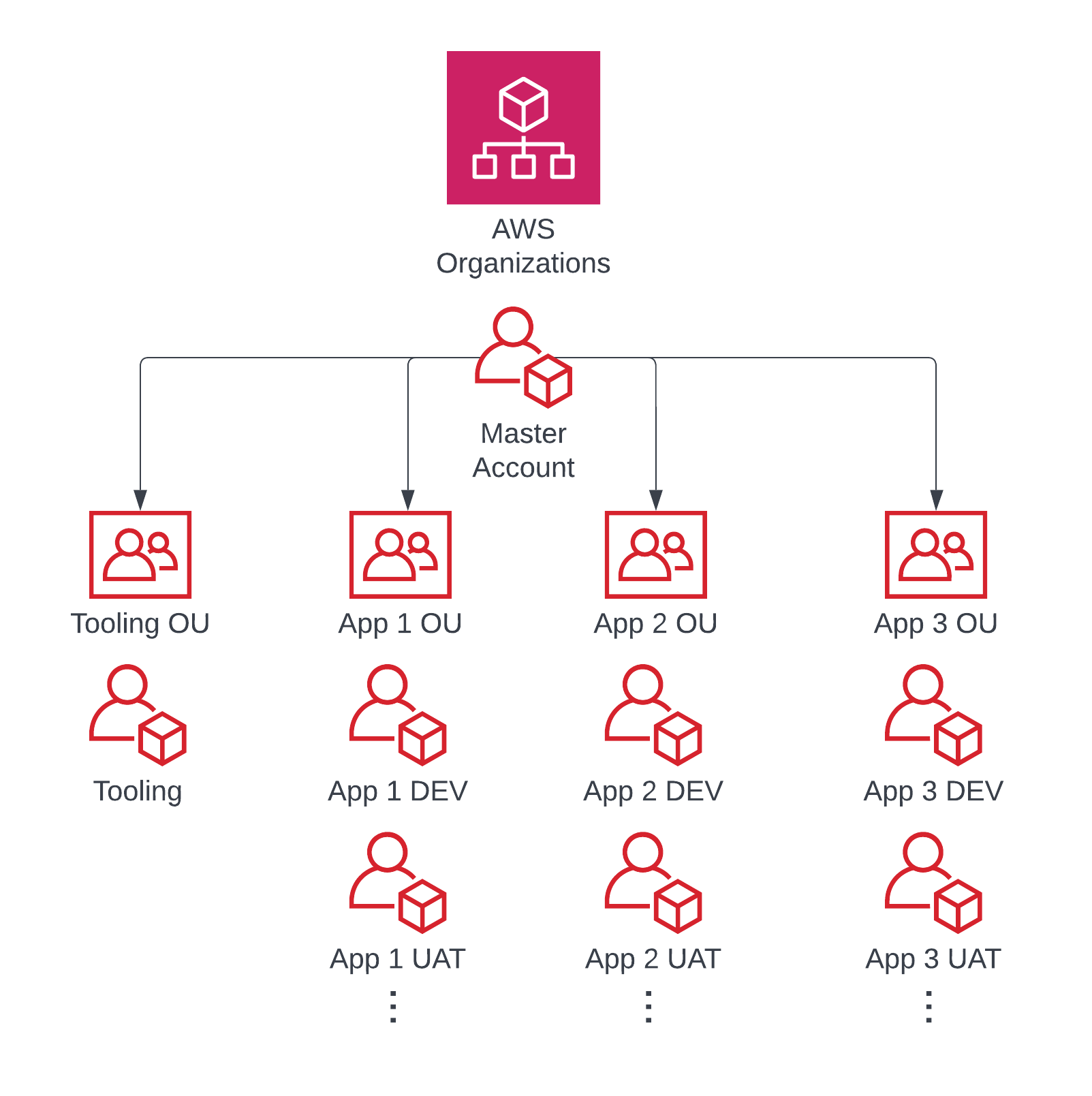
Infrastructure CI/CD vs Application CI/CD
Now i can already hear many of you cry out…
“CodePipeline for CI/CD sucks!”
I agree, kinda.
CodePipeline for application CI/CD leaves a lot to be desired and i personally wouldn’t use it for application CI/CD. I want more integration, flexibility and most importantly, speed!
But i’m not suggesting to use CDK Pipelines for application CI/CD, i’m talking about infrastructure CI/CD.
Application CI/CD
When we’re talking about application CI/CD, the final result looks very different depending on the clients requirements. But speed is generally the name of the game and I generally find code pipeline to be too slow and not be flexible enough.
| Stage | Unit Tests | Integration Tests | Code Coverage | Total Execution Time |
|---|---|---|---|---|
| Commit | ✅ | ❌ | ❌ | < 100 s |
| Pull Request | ✅ | ❓ | ✅ | < 300 s |
| Release Branch | ✅ | ✅ | ✅ | Up to 600 s |
Testing is a core part of Application CI/CD, and is a key reason application CI/CD pipelines are always so complex and unique. (and maybe why Jenkins is still around… plugins.)
This isn’t true for Infrastructure CI/CD.
Turn my code into infrastructure please, and do it again and again, every single time I make a change. Compared to application CI/CD, which will likely run many times a day over the lifetime of the product, Infrastructure CI/CD almost never runs.
So how does a Infrastructure CI/CD pipeline look like in AWS CDK?
Infrastructure CI/CD
- Start with a config file
from typing import Dict
from dataclasses import dataclass
@dataclass
class Networking:
vpc_cidr_range: str
@dataclass
class Environment:
networking: Networking
version_control_branch: str
@dataclass
class Tooling:
github_repo: str
codestar_connection_arn: str
tooling = Tooling(
github_repo="org/repo",
codestar_connection_arn="arn:aws:codestar-connections:ap-southeast-2:<account id>:connection/de4451769-9714-4323-a239-example123",
)
environments: Dict[str, Environment] = {
"DEV": Environment(
Networking(
vpc_cidr_range="10.10.10.0/20",
),
version_control_branch="dev",
),
}
- Create a CDK Stack
from env_config import environments
class NetworkStack(cdk.Stack):
def __init__(self, scope: Construct, id: str, env_name: str, **kwargs) -> None:
super().__init__(scope, id, **kwargs)
options = environments[env_name]
self.vpc = ec2.Vpc(self, "Vpc",
cidr=options.networking.vpc_cidr
)
- Wrap Stack in Pipeline Stage
class PipelineStage(cdk.Stage):
def __init__(self, scope: Construct, id: str, env_name: str, **kwargs) -> None:
super().__init__(scope, id, **kwargs)
self.network = NetworkStack(
self,
"network",
env=cdk.Environment(
account=self.node.try_get_context(f"account:{env_name}"),
region=self.node.try_get_context(f"region:{env_name}"),
),
env_name=env_name,
termination_protection=True,
)
- Add Pipeline Stack
from env_config import tooling, environments
class PipelineStack(Stack):
"""Create pipelines to deploy this stack and environment stacks"""
def __init__(self, scope: Construct, id: str, env_name: str, **kwargs) -> None:
super().__init__(scope, id, **kwargs)
project = self.node.try_get_context("project_name")
application_pipeline = pipelines.CodePipeline(
self,
f"{project}-pipeline",
pipeline_name=f"{project}-{env_name}-pipeline",
synth=pipelines.ShellStep(
"Synth",
input=pipelines.CodePipelineSource.connection(
repo_string=tooling.github_repo,
branch=environments[env_name].version_control_branch,
connection_arn=tooling.codestar_connection_arn,
),
commands=[
"npm install -g aws-cdk",
"pip install -r requirements.txt",
"cdk synth",
],
),
publish_assets_in_parallel=False,
cross_account_keys=True,
self_mutation=True,
docker_enabled_for_synth=True,
)
application_pipeline.add_stage(
PipelineStage(
self,
f"{env_name}",
env=cdk.Environment(
account=self.node.try_get_context(f"region:{env_name}"),
region=self.node.try_get_context(f"region:{env_name}"),
),
env_name=env_name,
),
pre=[pipelines.ManualApprovalStep("Deploy Infrastructure")],
)
- Add Pipeline Stack to app.py
from env_config import environments
for env_name, environment in environments.items():
region = app.node.try_get_context("region:tooling")
account = app.node.try_get_context("account:tooling")
project = app.node.try_get_context("project_name")
PipelineStack(
app,
f"{project}-pipeline-{name}",
env=cdk.Environment(
account=account,
region=region,
),
env_name=env_name,
)
Boom! You the Infrastructure as Code that creates a pipeline in a tooling account, which deploys a Stack into several accounts of your choice.
- Write IaC code once, deploy many places
- Simple to expand
- Fully automated CI/CD.
How do I deploy?
- Bootstrap
- Target accounts:
cdk bootstrap aws://<target account>/<region> --trust <tooling account> --trust-for-lookup <tooling account> --cloudformation-execution-policies 'arn:aws:iam::aws:policy/AdministratorAccess' --profile <target account profile>
- Tooling account:
cdk bootstrap aws://<tooling account>/<region> --cloudformation-execution-policies 'arn:aws:iam::aws:policy/AdministratorAccess' --profile <tooling account profile>
cdk synthcdk deploy project-pipeline-DEV --profile tooling-account-profile
Conclusion
That wasn’t so painful!
Behind the scenes, CDK has deployed all the cross account roles and permissions so you never ever need to think about that again. Just write CDK Code and watch it deploy to 5 accounts.
So remind me, why should i use Terraform when i prefer to use Python over HCL, and my cross account woes are a think of the past?
Tooling Account Pipelines